Architectural Approaches of Federated Machine Learning in Investment Banking
The concept of federated learning was first proposed by Google in 2017. Google’s main idea is to build machine-learning models based on datasets that are distributed across multiple devices while preventing data leakage and visibility. This type of machine learning does not lack of its own problems, such as communication cost in massive distribution, unbalanced data distribution, and device reliability. These factors must be taken into consideration when deciding whether to dive into this type of technologies, if only for the optimization difficulties. In addition, data is partitioned by user, entities or device Ids, therefore, horizontally in the data space.
But when it comes to data privacy-preserving machine learning approximations in a decentralized collaborative-learning setting, the advantages start to overcome the difficulties. Depending on the parties and data distribution involved, the privacy necessities or even the encryption adopted, multiple architectural approaches have been developed (Differential Privacy, Secure Multiparty Computation, Homomorphic Encryption, ...). But overall, there are two main architectural implementations of federated machine learning.
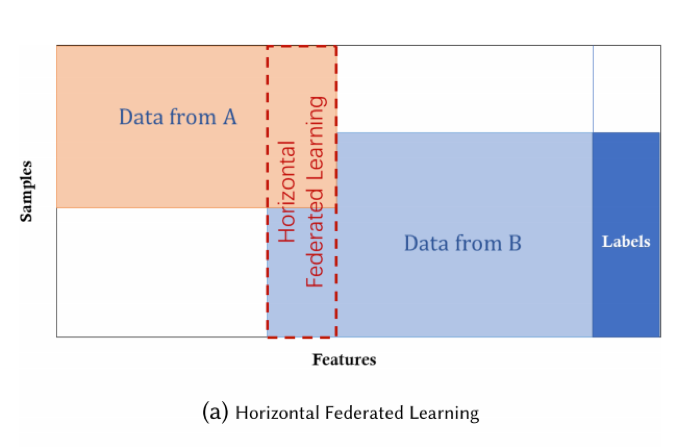
1. Horizontal Federated Learning
Horizontal federated learning, or sample-based federated learning, is introduced in the scenarios in which datasets share the same feature space but different space in samples.
Imagen 1.png43.5 KB For example, two regional banks may have very different user groups from their respective regions, and the intersection set of their users is very small. However, their business is very similar, so the feature spaces are the same. A collaboratively deep-learning scheme in which participants train independently and share only subsets of updates of parameters could make sense in this situation.
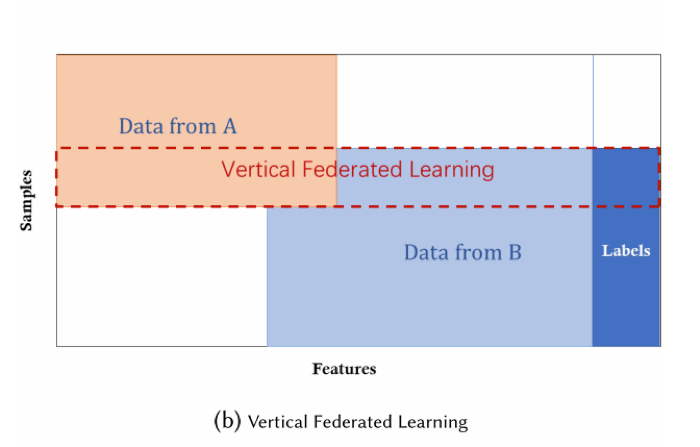
2. Vertical Federated Learning
Privacy-preserving machine-learning algorithms have been proposed for vertically partitioned data, including cooperative statistical analysis, association rule mining, secure linear regression, classification, and gradient descent.
Imagen 2.png44.9 KB For instance, a vertical federated-learning approach would be fitting to train a privacy-preserving logistic regression model. The effect of entity resolution on learning performance and applied Taylor approximation to the loss and gradient functions so that homomorphic encryption can be adopted for privacy-preserving computations. Vertical federated learning or feature-based federated learning is applicable to the cases in which two datasets share the same sample ID space but differ in feature space.
For example, consider two different companies in the same city: one is a bank and the other is an ecommerce company. Their user sets are likely to contain most of the residents of the area; thus, the intersection of their user space is large. However, since the bank records the user’s revenue and expenditure behavior and credit rating and the e-commerce retains the user’s browsing and purchasing history, their feature spaces are very different. Suppose that we want both parties to have a prediction model for product purchases based on user and product information.