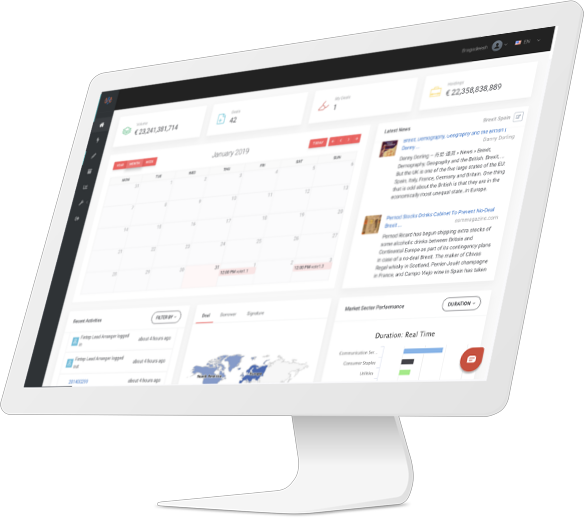
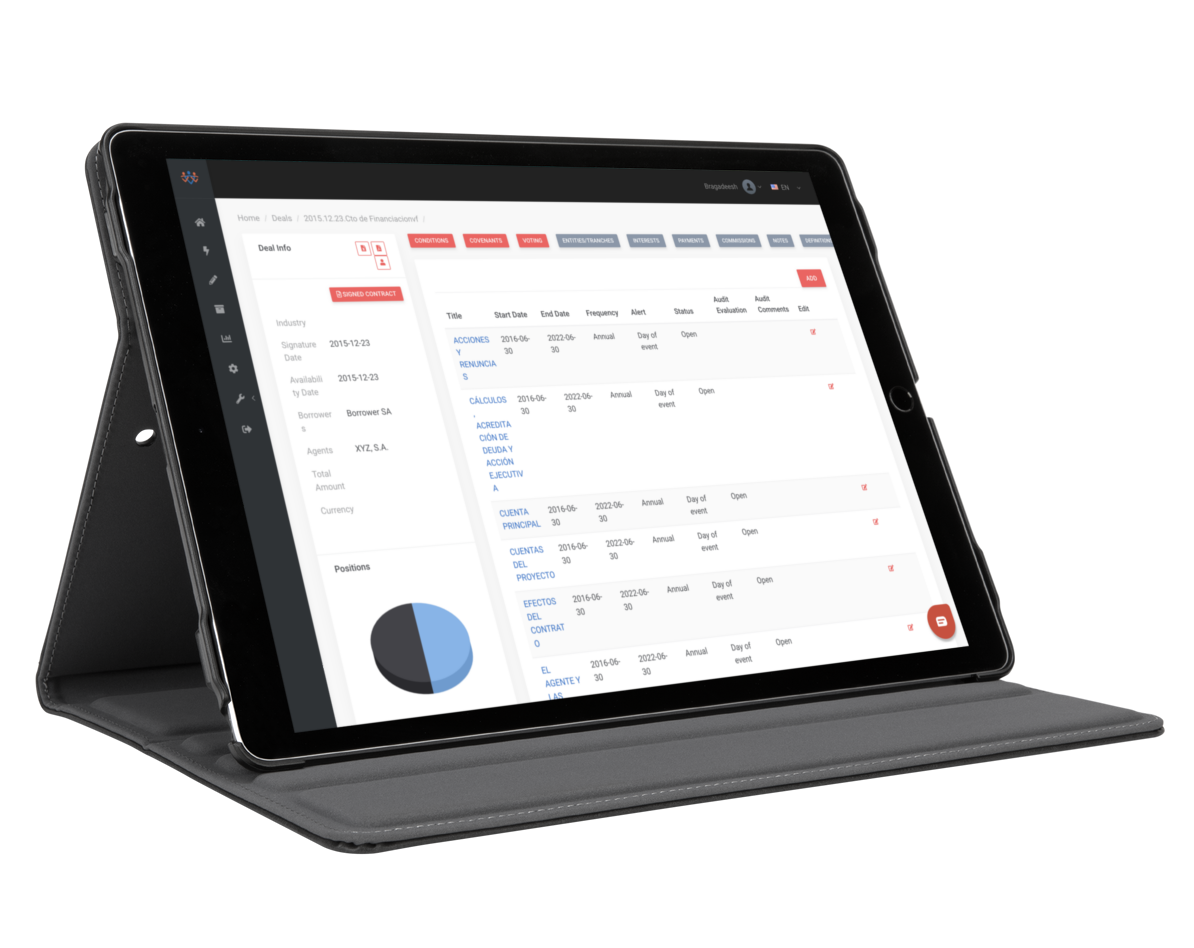
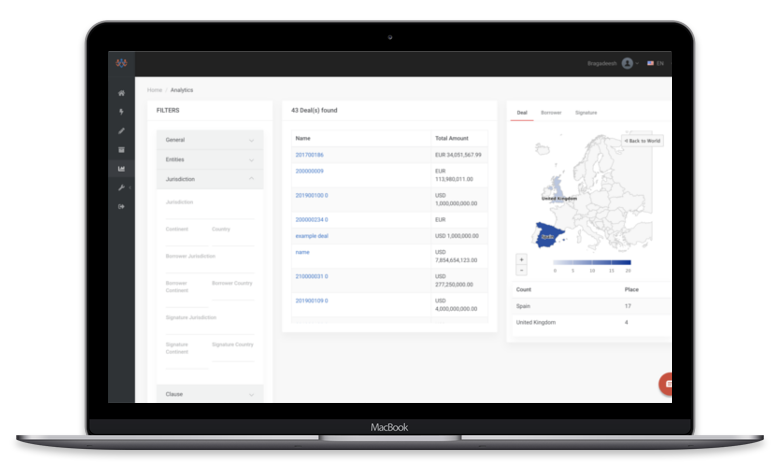
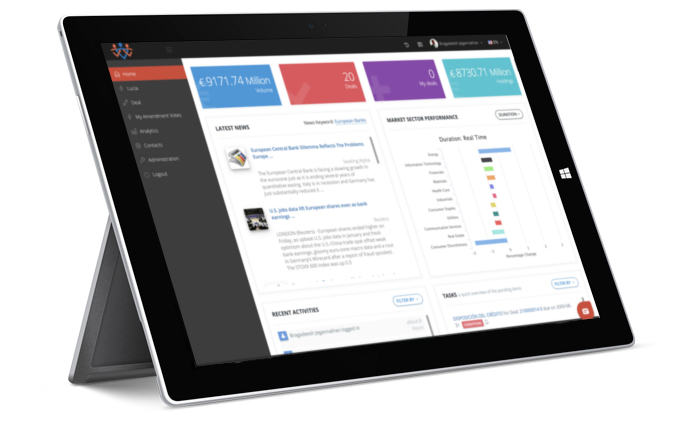
Fintep provides an IT platform that automates and manages the loan lifecycle from processing to collection
Realtime Monitoring
Boost process standards and monitoring: enhance automation and business process management
Centralized Capabilities
Improve connectivity between different stakeholders and eradicate silo-based systems with partial integration capabilities that cause data redundancy and delayed loan processing
Automated Workflows
Eliminate monotonous, vain tasks such as manual gathering of data, filling out multiple forms and periodic request of deal documents
Transparency across transactions
Maintain a unique monitoring system across all transactions to encourage transparency and avoid disputes
Superior Insights
Avoid usage of excel based analysis clauses and unnecessary delays in calculating risk exposure events. Structure the right loan solution to each client
One Product for everyone
Fintep is a one-stop solution for every level within your organization
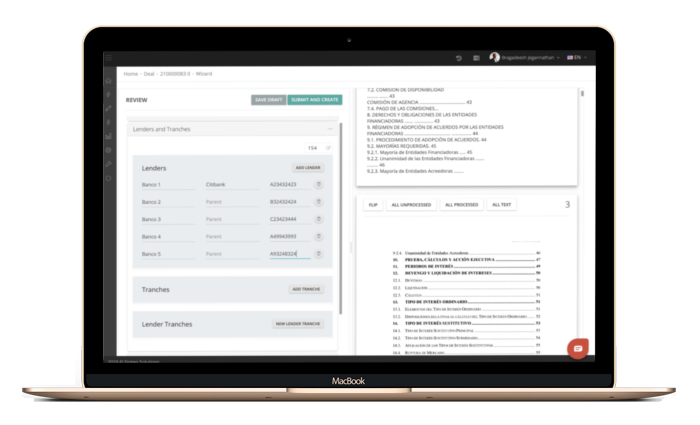
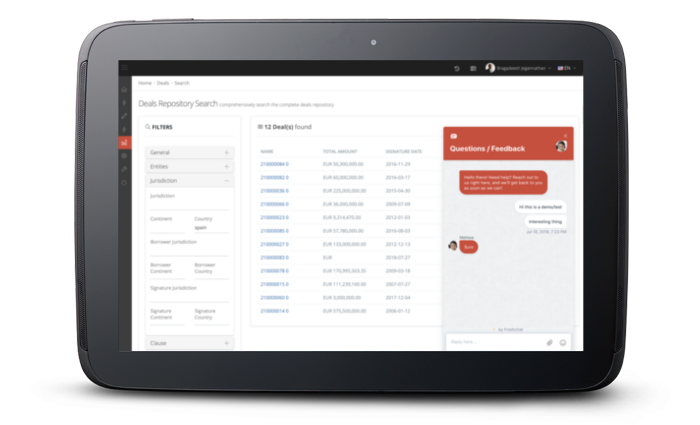
Review Loan Book by Country, Risk, Industry, Agencies and Entity exposure
Present main impacts on Loan Book in terms of efficiencies, reduced time-to-market, agility or increased flexibility
Avoid third party expensive Data Rooms
Portfolio Managment
Monitor project execution and KPIs; review risks and set up correction measures to ensure fulfillment of global objectives
Make key decisions and escalate issues if necessary
Ensure coordination across work streams and timely participation of all stakeholders
Eliminate unnecessary expenses such as lawyer Fees and Internal Costs to run Amendments/Waiver/Variation Order approvals
Milestone Monitoring
Follow up of daily Monitoring Milestones, identifying possible deviations, risks, synergies, additional opportunities to deliver or enhance capabilities, lessons learnt
Identify dependencies across work streams
Make operational decisions and escalate management decision if/when necessary
Eliminate Lawyer Fees regarding Contract Information Extraction and Interpretation
Search Clause examples through our loan book filter
In today’s current corporate lending solutions, manual workflows, paper-based documentation and silo-based systems make the entire lending process complex and time-consuming. The declining interest rates have put pressure on financial institutions to automate their lending processes. More banks are now looking to incorporate an effective system that ensures faster processes, better operational efficiency and full capitalization on the lending opportunities available.
If banks do not transform their lending system now, they risk losing their business to other efficient banks and shadow lenders such as institutional investors, P2P lenders and business development companies.
It's time for banks to transform their corporate lending solution to analyze borrowers' global risk faster and more efficiently; adhere to changing regulatory norms and meet financial needs of all types of organizations from small companies to large multinationals with operations across the globe.
Founded in 2017, Fintep plunges into this industry to build and deploy an innovative, next-generation technology software and cloud ecosystem. Our SaaS business model means that we can serve customers effectively, regardless of their size or location; from global financial institutions to community banks and credit unions.
Fintep brings deep expertise and an unrivaled range of pre-integrated solutions from transaction banking to lending, and capital markets. With a global footprint and the broadest set of financial software solutions available on the market, Fintep manages more than 800 Billion EUR loans over 32 different jurisdictions including the top 100 banks globally.
Paris, France – Fintep is pleased to announce its strategic partnership with Aether Financial Services. Fintep’s advanced Artificial Intelligence technology, Lucia, will now be available to Aether Financial Services’ suite of tools. The partnership will bring together Fintep’s highly flexible AI product with Aether Financial Services’ comprehensive financial services expertise in transaction management and agency services.
Captura de pantalla 2020-11-25 a las 11.28.52.png31.2 KB
The partnership with Fintep will allow Aether Financial Services to assist clients with a product powered by advanced machine learning technology across a multitude of use cases to optimize the management of their agencies and streamline their operations. This will enable Aether Financial Services to help clients process, extract, and analyze textual qualitative data faster, and deliver a seamless transaction/portfolio management solution and workflow that improves efficiencies and delivers value throughout the value chain.
Edouard Narboux, Founding Partner at Aether Financial Services said:
“We are delighted to announce this new strategic partnership with Fintep. We believe AI technologies are at the forefront of digital transformation in capital markets, and we want to be a part of that transformation. It is at the core of our DNA to provide the best service to our clients and by combining the know-how and expertise of our agency teams with Fintep’s cutting-edge AI technology, we will be able to deliver an unparalleled value proposition to our clients.”
Antonio Garcia, Chief Executive Officer of Fintep added:
“We have worked closely with Aether Financial Services to bring our best-in-class AI and agency technology to its diverse list of clients. Aether Financial Services’ expertise is a fantastic complement to our product’s unique capabilities, and we believe this partnership will bring real benefits to our end users. Together, it is a compelling proposition, and we are looking forward to working with Aether Financial Services to bring it to market.”
Andres Torrenti, Managing Director at Aether Financial Services added also:
“For Aether Financial Services, this partnership is a perfect fit. Fintep’s unique AI-powered platform integrates and extracts beautifully different data sources, and truly unlocks the power to use data to drive enterprise value, increase efficiencies across the value chain, and reduce exposure to operational risk through digitalization.”
About Aether Financial Services:
Aether Financial Services is a leader in post-transactional services, assisting issuers and investors, financial advisors, and lawyers in the valuation, closing management, and administration of debt and M&A documentation. Founded in 2015 to address the growing need for highly specialized agents in international loan and capital markets, Aether Financial Services is a leading independent transaction manager across different asset classes and jurisdictions. To learn more, visit us at www.aetherfs.com, and follow us on LinkedIn.
About Fintep:
Founded in 2017, Fintep plunges into this industry to build and deploy an innovative, next-generation technology software and cloud ecosystem. Our SaaS business model means that we can serve customers effectively, regardless of their size or location; from global financial institutions to community banks and credit unions. Fintep brings deep expertise and an unrivaled range of pre-integrated solutions from transaction banking to lending, and capital markets. With a global footprint and the broadest set of financial software solutions available on the market, Fintep manages more than 5 Trillion USD loans over 32 different jurisdictions including the top 100 banks globally. Visit us at https://fintep.com/ and follow us on LinkedIn.
For the past few years, the banking industry has been exploring the benefits of incorporating machine learning and artificial intelligence into their industry. In this regard, there have been significant advances in security, customer behavior recognition, sentiment analysis, trading recommendation systems, etc…
But after a few years, the industry has seen that the data that they have can only take them so far. Challenges like data quality, data tagging, pattern correlation vs causation, etc.… hit a wall when you only have so much data. When training an AI, engineers need more or different data that the banking entity currently has. And accessing external data sources often proves an impossible task due to security or privacy issues.
It is due to this necessity that federated learning has come into the light, since it permits different players to cooperate and share training data without compromising the privacy or security of their datasets. Not only that, but the extracted intelligence can be used for more than one industry player, encouraging cooperation between competitors in certain fields or different type of industries when their interests meet.
Federated learning also provides systems to adequately reward those players that contribute with higher or better quality data to the model training and to reject the entities whose data is of no value to the model that is being trained.
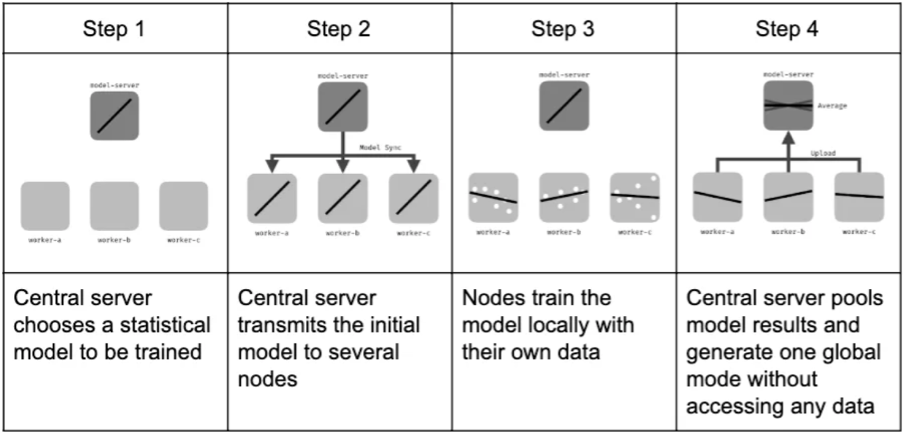
Imagen 1.png124 KB
If configured to do so, in the above image the model-server, implemented by a neutral entity, is capable of addressing the quality and quantity of the data that each player is bringing into the equation, and reducing the impact or, in extreme cases, flat out rejecting the data of one of the federated entities. Either by creating a new model from scratch or by re-training a model to include a new banking industry's intelligence, this approach ensures that the prediction quality will always be rewarding those who contribute the most.
Both in supervised and unsupervised approaches, it is clear that this technique can have a great value for future endeavors in machine learning. It will be through cooperation and not competition that the most powerful and advanced AI will be created in the future, simply because this approach will ensure access to the most varied and higher quality data, and in Fintep we are embracing this change with enthusiasm. As an African proverb says: “if you want to go fast, go alone. If you want to go far, go together”
Some banks are experimenting with rapid-automation approaches and achieving promising results. These trials have proved that automating end-to-end processes, which used to take 12 to 18 months or more, is doable in 6 months, and with half the investment typically required.
bank3-1.jpg122 KB
A European bank recently decided to automate its account-switching process. First, a team of IT, operations, and business-process experts analyzed existing processes from the customer, efficiency, and risk perspectives. The analysis uncovered several issues: more than 70 percent of the applications were paper-based, and of those, 30 to 40 percent contained errors and required reworking; applications often got stuck in one data-verification step for more than five days before being processed, and because of a lack of any IT integration, branch and back-office staff had to enter data manually from several systems into the workflow.
The team then defined what it wanted the process to look like, giving priority to operational and business impact (for instance, how much labor could be saved through automation) and to feasibility (such as how many new interfaces or changes to legacy systems would be required). The team focused on simplifying the process steps and procedural requirements at each stage—streamlining the information required from the customer and eliminating redundant verification steps—to reduce the complexity of the IT solution.
Using this design, the team carefully evaluated the possible integration options. It decided to use a combination of business-process-management software and Fintep’s AI extraction tool, in addition to the legacy systems, to create an automated and digitized workflow that did not significantly change existing IT systems. Daily huddles and weekly builds,2 which were immediately tested by users, ensured that the solution met the requirements, and kept users engaged.
As a result, the amount of time back-office staff spent handling account changeovers fell by 70 percent; the time customers needed to adjust to the switch was reduced by more than 25 percent. The cost-benefit ratio for this project was also significantly better than it had been in previous automation efforts: the project generated a return on investment of 75 percent and payback in just 15 months.
This European bank’s experience illustrates three principles that make success more likely when automating operations:
Consider business priorities to simplify the process. Automating inefficiencies or unnecessary product features embedded in historical processes is pointless. By first defining the best processes from the customer, business, and risk perspectives—taking a lean approach to process design—banks can significantly reduce what actually needs to be automated, which in turn lessens the cost, risk, and implementation time. A truly cross-functional team consisting of operations, IT, and business experts, as well as strong project governance, is required to design and enforce such optimal end-to-end solutions. The involvement of top management across multiple functions—operations, retail, and IT, for instance—is also essential.
Use multiple integration technologies and approaches. The right mix of integration solutions, backed by a solid evaluation of each solution’s time to market and contribution to architectural complexity, enables banks to automate most of their manual interventions without rewriting or substituting legacy architectural building blocks. For example, banks are successfully creating workflow systems by overlaying business-process-management tools that connect separate legacy systems, which in turn eliminates manual data entry and related errors across end-to-end processes. This evaluation is not straightforward, however, and requires a thorough understanding of what the market for integration solutions has to offer.
Prepare the IT shop for agile-development methods. To achieve rapid development cycles and use off-the-shelf solutions successfully, IT departments must build skills beyond their traditional capabilities. In particular, they should assess the software market and apply the right solutions; and capable of working seamlessly with business and operations counterparts.
As some banks experiment with this rapid-automation approach, and the impact of initial pilots resounds throughout the organization, IT and operations teams will feel pressured to integrate all end-to-end and back-office processes. All too often, however, efforts to scale up these initiatives are short-lived. IT architecture teams, concerned that they will not master unfamiliar integration solutions, or that additional efforts will make the IT landscape even more complex, may react warily. Meanwhile, operations and business personnel push to automate everything everywhere as soon as possible, without proper planning and evaluation. These pressures spread IT teams too thin, diverting their attention from the largest areas of opportunity. Because such projects are carried out much more quickly than traditional development efforts, IT departments struggle to set up the necessary infrastructure on time, and the teams are not focused on the value or necessity of additional features.
To overcome these obstacles, banks must design and orchestrate automation-transformation programs that prioritize and sequence initiatives for maximum impact on business and operations. They also need to define a target IT architecture (both applications and infrastructure) that uses a variety of integration solutions while maintaining a system’s integrity.
Successful large-scale automation programs need much more than a few successful pilots. They require a deep understanding of where value originates when processes are IT enabled; careful design of the high-level target operating model and IT architecture; and a concrete plan of attack, supported by a business case for investment.
Another European bank launched a strategic initiative to shrink its cost base and increase competitiveness through superior customer service. Upon completion of the first successful pilots, the bank’s automation program consisted of three phases.
In phase one, the bank examined ten macro end-to-end business processes, including retail-account opening and wholesale customer service requests, to identify the automation potential and to prioritize efforts.
In phase two, the architecture was designed and a plan of attack formulated. The bank took three critical actions:
It decided which processes would be fully automated, partially automated, or fully manual, based on four key tests. The tests determined whether a process was too complex to automate (for example, deal origination and structuring), whether regulation required human intervention (for instance, the financial-review process), whether or not the process was self-contained (that is, dependent on multiple customer or third-party interactions), and whether manual touchpoints added value to the customer relationship (for example, product inquiries).
It designed the building blocks of the target application architecture, which consisted of legacy systems and off-the-shelf applications such as Fintep Software, as well as the IT infrastructure requirements, to provide timely and necessary computing and storage.
It derived a design-based holistic business case for the automation program and defined the rollout plan.
In phase three, the bank implemented the new processes in three- to six-month waves, which included a detailed diagnostic and solution design for each process, as well as the rollout of the new automated solution.
This approach helped the bank to deliver business and operational benefits rapidly and successfully. The program paid for itself by the second year and kept implementation risks under control.
Testimonials
Fintep’s ensured that our syndicated loans caught up with the other asset classes thanks to shorter settlement cycle and more efficient processing. Ultimately, Fintep reduced our exposure to risk, increased our operational margins by 57% and improved our customer service.
We can now compare covenants across similar deals, capital structures, and filter according different events; this was simply impossible to do it before.
It is an interesting and very powerful platform. I haven't seen anything on the market that is nearly as complete as this.